ARM vs x86
Background
Roboquant is an algo-trading platform written in Kotlin, and more importantly for this article, runs on a Java Virtual Machine (JVM).
When testing and optimizing a trading strategy, you’ll need to run thousands of simulations over large historic data sets. In order to speed up this process, roboquant is built to efficiently (low-memory, high-throughput) run these simulations in parallel.
Question that than remains: what is the best machine to run these simulations on? To take some of the guess work out of the equation, roboquant comes with a dedicated performance test. The test measures the performance of the maximum throughput expressed as "the number of candles per second".
And since this test doesn’t rely on network- or disk-io, it is a good indicator of the overall CPU architecture performance.
The 2 candidates
Cloud infra is a cost-effective way to perform these types of elastic workloads. So we selected two similar AWS EC2 instances for the comparison test.
-
Intel/AMD based instance (x86-64)
-
ARM based instance (AArch64)
Other than the CPU architecture, these two instances have almost the same configuration and cost associated with them. The two instances also both run OpenJDK 17 and Ubuntu-22.04 (AWS standard EC2 images) without further tuning.
| EC2 Instance | Architecture | Type | vCPU | Memory | Cost/hour |
|---|---|---|---|---|---|
c6a.16xlarge |
x86-64 |
AMD Epyc third generation |
64 |
128GB |
$2.45 |
c7g.16xlarge |
AArch64 |
AWS Graviton third generation |
64 |
128GB |
$2.31 |
Results
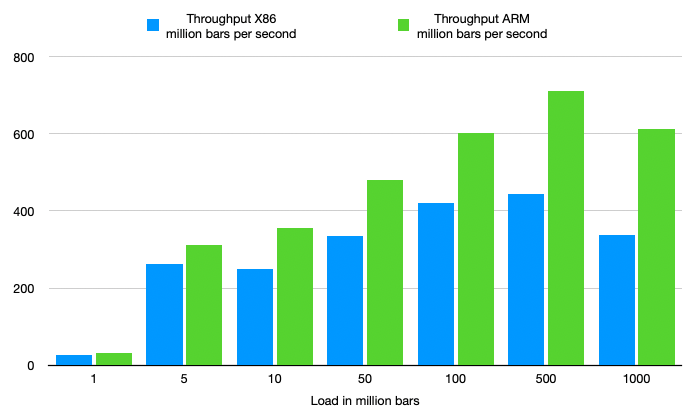
The outcome of running the performance test on both machines might come as a bit of surprise. Since JVM has been running on x86-64 hardware much longer than Arm64, you might expect it also to perform better on that platform. But actually, the opposite is true.
| Load (M) | x86 throughput (M/s) | ARM throughput (M/s) | Difference |
|---|---|---|---|
1 |
27 |
31 |
15% |
5 |
263 |
312 |
19% |
10 |
250 |
357 |
43% |
50 |
335 |
480 |
43% |
100 |
421 |
602 |
43% |
500 |
443 |
711 |
60% |
1000 |
337 |
612 |
82% |
As is clear from the above chart and table, the performance on ARM is significantly better than on x86:
-
The maximum throughput on x86 is 443 million candlesticks per second, while on ARM it is 711 million. So at maximum throughput, ARM is 60% faster, while at a similar or slightly lower price point.
-
If we look at the biggest load of 1 billion bars, ARM is 82% faster than x86.
For those interested in the exact output of the performance tests:
x86
_______
| $ $ | roboquant
| o | version: 1.5.0-SNAPSHOT
|_[___]_| build: 2023-05-11T06:49:52Z
___ ___|_|___ ___ os: Linux 5.15.0-1031-aws
()___) ()___) home: /home/ubuntu/.roboquant
// / | | \ \\ jvm: OpenJDK 64-Bit Server VM 17.0.6
(___) |_________| (___) memory: 30688MB
| | __/___\__ | | cpu cores: 64
/_\ |_________| /_\
// \\ ||| ||| // \\
\\ // ||| ||| \\ //
()__) ()__)
/// \\\
__///_ _\\\__
|______| |______|
CANDLES ASSETS EVENTS RUNS FEED FULL SEQUENTIAL PARALLEL TRADES CANDLES/S
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1M 10 1000 100 7ms 19ms 123ms 37ms 1K 27M
5M 50 1000 100 4ms 12ms 241ms 19ms 5K 263M
10M 50 2000 100 12ms 17ms 456ms 40ms 10K 250M
50M 100 5000 100 18ms 85ms 1833ms 149ms 50K 335M
100M 200 5000 100 34ms 167ms 3481ms 237ms 100K 421M
500M 500 10000 100 172ms 630ms 21594ms 1128ms 500K 443M
1000M 500 20000 100 345ms 1387ms 44519ms 2962ms 1000K 337M
ARM
_______
| $ $ | roboquant
| o | version: 1.5.0-SNAPSHOT
|_[___]_| build: 2023-05-11T06:50:00Z
___ ___|_|___ ___ os: Linux 5.15.0-1031-aws
()___) ()___) home: /home/ubuntu/.roboquant
// / | | \ \\ jvm: OpenJDK 64-Bit Server VM 17.0.6
(___) |_________| (___) memory: 30688MB
| | __/___\__ | | cpu cores: 64
/_\ |_________| /_\
// \\ ||| ||| // \\
\\ // ||| ||| \\ //
()__) ()__)
/// \\\
__///_ _\\\__
|______| |______|
CANDLES ASSETS EVENTS RUNS FEED FULL SEQUENTIAL PARALLEL TRADES CANDLES/S
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1M 10 1000 100 6ms 32ms 267ms 32ms 1K 31M
5M 50 1000 100 4ms 17ms 241ms 16ms 5K 312M
10M 50 2000 100 13ms 28ms 503ms 28ms 10K 357M
50M 100 5000 100 34ms 130ms 2335ms 104ms 50K 480M
100M 200 5000 100 50ms 213ms 4393ms 166ms 100K 602M
500M 500 10000 100 256ms 798ms 19787ms 703ms 500K 711M
1000M 500 20000 100 495ms 1428ms 39755ms 1633ms 1000K 612M
Reasons
There are two main reasons why we observe these large differences in performance:
-
Instructions per cycle
The JVM doesn’t utilize all the x86 instructions that are available. Compared to something like a LLVM compiler, the JIT compiler is more limited in the instructions it actually compiles to.
For example, the JVM only recently started using AVX512 instructions and only for limited use-cases. So although the x86 has more powerful instructions available, the JIT compiler doesn’t always use them.
And this is of course of great benefit to ARM, since the instruction set is smaller by design, but the number of instructions it can process per clock-cycle is higher. So from this perspective, a "RISC" architecture like ARM is better suited to the JIT compiler.
-
Memory speed
Although the performance test is CPU bound, memory speed (bandwidth and latency) plays an important role. Unfortunately, AWS doesn’t provide this metric for the selected instance. So instead, we run a small Linux benchmark utility (
mbw) to get an approximation of the memory performance. We use smaller 1MB memory blocks to reflect JVM memory usage patterns:x86: AVG Method: MEMCPY MiB: 1.00 Copy: 12836.970 MiB/s ARM: AVG Method: MEMCPY MiB: 1.00 Copy: 18761.726 MiB/s
Clearly, the memory bandwidth of the ARM instance is better. And this is easily explained since Graviton uses DDR5 memory while the Epyc platform still uses the slower DDR4 memory modules.
One might argue that this is just a temporary situation, and in the remaining of 2023 several new x86 DDR5 server platforms will be launched. And while this might be true, the complexity of the x86 chips combined with the fact that there are only two chip designers (Intel & AMD), means it will always be lacking when it comes to more purpose-built systems.
Future of the JVM on ARM
There are still several areas where the performance can be improved, triggered by both JVM and ARM improvements:
-
The CPUs used in the Graviton machine are actually not that impressive (yet). When we compare the performance of an 8-core Graviton against an 8-core Apple M2 chip, it becomes clear there is still a lot to be gained.
The Apple M2 8-core CPU performs over 75% better than a similar sized Graviton instance. If we extrapolate this to 64 cores and assume other ARM CPU designers will catch up, the ARM CPU is potentially a whopping 210% faster than x86.
-
ARM is quickly gaining traction for server-side computing. So it is not unreasonable to assume that newer ARM instruction sets will support these types of work-loads even better (ARMv9 and onwards).
-
The JIT compiler gets further optimized for the ARM platform. Support for AArch64 is relatively new, with the first decent port only included in JDK 11. So again, it is reasonable to expect that the JIT compiler will take better advantage of the ARM architecture in the future.